Maschinelles Lernen und künstliche Intelligenz für eingebettete Systeme

Künstliche Intelligenz hat das Potenzial dazu, hochdimensionale Daten performant zu verarbeiten. Wir untersuchen, wie man beispielsweise Tiefe Neuronale Netzwerke oder Convolutional Neural Networks auf eingebetteten Systemen einsetzen kann. Aber auch für andere Konzepte des Maschinellen Lernens wird erforscht, wie sich diese in ressourcenbeschränkten Umgebungen nutzbringend verwenden lassen.
Mit Fortschritten in der Forschung im Bereich der Künstlichen Intelligenz kommen immer mehr Einsatzgebiete für diese in Frage. Die traditionell ressourcenhungrigen Technologien halten auch verstärkt Einzug in kleine, mobile und sogar tragbare Systeme. Diese Entwicklung ist möglich, weil spezialisierte Hardware sowie findige Optimierungen den Ressourcen- und Energiebedarf drastisch verringern und patente Automatisierungen und Vorlagen zunehmend Hürden für die Anwendung beseitigen.
Hybride Plattformen mit KI-Hardwarebeschleunigung
Ein Teil unserer Forschung besteht folglich darin, diese Spezialhardware in Form von KI-Hardwarebeschleunigern zu entwerfen und zu implementieren. Dafür kommen bei uns flexible FPGAs zum Einsatz, mit denen sich beliebige KI-Modelle günstig und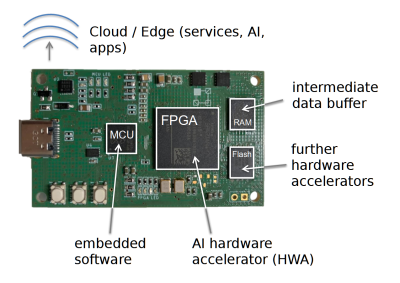
effizient als Hardware umsetzen lassen.
Die hybride Hardwareplattform Elastic Node, welche Teil des Elastic-AI-Ökosystems ist, stellt hierbei gleichzeitig Frucht und Werkzeug unserer Forschung dar und soll vor allem Ansprüchen an Nutzbarkeit, Anpassungsfähigkeit sowie Überwachbarkeit gerecht werden und dabei effizient sein.
Darum untersuchen wir für diesen Bereich auch adäquate hardwarenahe Optimierungsmöglichkeiten. Denn durch genaue Kenntnis der Hardware lassen sich in vielen Bereichen Ansätze finden, mit denen man die verfügbaren Ressourcen voll ausschöpfen kann. So gibt es beispielsweise Einsparungspotenzial durch Umsetzung einzelner Modellschichten mit quantisierten Aktivierungsfunktionen mittels LUTs, oder durch Modellschichten, die nicht die volle Taktrate benötigen, Parallelisierung in der ALU und viele andere Ansätze.
Ansprechpartner: Chao Qian, M.Sc.
Optimierung von Neuronalen Netzwerken
Generell spielen in unserer Arbeit Optimierungen, hard- wie softwareseitig, eine große Rolle.
Es handelt sich um ein weites Feld; wir konzentrieren uns derzeit hauptsächlich auf stark quantisierte Neuronale Netzwerke und Transformer.
Dabei untersuchen wir allgemein Optimierungen beim Training der Netzwerke und streben möglichst schnelle wie effiziente Berechnungen an, beispielweise durch den Einsatz separierbarer Faltungen.
Zudem erlaubt es bei quantisierten neuronalen Netzwerken (QNN) eine geringe Bittiefe von zwei oder weniger Bit im Zusammenspiel mit der Beschaffenheit von FPGAs, Operationen innerhalb des Netzwerkes vorauszuberechnen und die entsprechenden Ergebnisse für schnellstmöglichen Zugriff in den LUTs der konfigurierbaren Logikblöcke zu hinterlegen.
Ansprechpartner: Lukas Einhaus, M.Sc.
Transformatornetzwerke, ursprünglich für Übersetzungsaufgaben konzipiert, eignen sich in abgewandelter Form sehr gut für die Prognose von zukünftigen Zeitreihenwerten, was sie für gewisse Regelungsaufgaben attraktiv macht. Doch um wie im RIWWER-Projekt in verteilten Systemen im Abwassernetz zum Einsatz kommen zu können, müssen sie leichtgewichtiger und schneller gemacht werden. Auch hierbei ist Quantisierung das Mittel unserer Wahl.
Ansprechpartnerin: Tianheng Ling, M.Sc.
Spikesortierung und Online-Training für Quantisierte Neuronale Netzwerke

Eine weitere spannende Anwendung von Quantisierten Neuronalen Netzwerken, die aktuell im Forschungsprojekt Sp:Ai:Ke erforscht wird, ist die Zeitreihenanalyse von (echten biologischen) neuronalen Signalen.
Die Aufzeichnungen solcher Signale umfassen immer ganze Signalbündel sowie eine gewisse Hintergrundaktivität. Um ein differenziertes Bild einzelner neuronaler Aktivitäten zu bekommen, bedarf es daher geschickter Verarbeitung der Signale, die noch dazu adaptive Qualitäten besitzen muss.
Genauer gesagt werden zur Laufzeit (also online) aufgrund des neuronalen Drifts Anpassungen der Signalklassifizierung nötig, das eingesetzte Netzwerk muss mit wenigen exemplarischen Daten kontinuierlich nachjustiert bzw. -trainiert werden.
Ansprechpartner: Leo Buron, M.Sc.
Hardwaresensitive Neuronale Architektursuche
Die ideale neuronale Architektur für den jeweiligen Anwendungsfall zu finden, kann viel Zeit und Ausprobieren erfordern.

Die Neuronale Architektursuche (auch NAS) automatisiert diesen Gestaltungsschritt und findet teilweise Architekturen, die manuell erstellte übertreffen. Ferner lässt sich sogar die nötige Ressourcenabschätzung durch ein Tiefes Neuronales Netzwerk automatisieren.
Auf diese Weise wird der bedarfsangepasste Einsatz von Neuronalen Netzwerken wesentlich vereinfacht.
Das Verfahren, auf dem zur Zeit unser Hauptaugenmerk liegt, beruht auf evolutionären Algorithmen und findet optimale Architekturen durch kontinuierliches Mutieren und Aussortieren von Kandidaten.
Unsere Anforderungen beinhalten typischerweise den effizienten Betrieb auf ressourcenbeschränkter Hardware, darum fließen Hardwarekosten wie Latenz oder Energieverbrauch als Optimierungskriterien in die Architektursuche mit ein.
Unsere Forschung fokussiert sich hierbei abermals auf Anwendungsfälle aus den Bereichen Signalverarbeitung und Zeitreihenanalyse, beispielsweise um die besten WaveNet-basierten Architekturen für die Simulation von verschiedensten, teilweise komplexen Audioeffekten zu finden.
Ansprechpartner: Christopher Ringhofer, M.Sc.